Overview
最近几篇 self-distillation 的论文,核心结构非常一致:
- Self-Distillation Enables Continual Learning
- Reinforcement Learning via Self-Distillation
- Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
这三篇工作都不是传统意义上的“大模型蒸馏小模型”。更准确的表述是:同一个模型同时扮演 student 和 teacher,teacher 只是比 student 多看了一份特权上下文。
统一记号后,student policy 可以写成:
$$ \pi_\theta(\cdot\vert x,\hat y_{< t}) $$
teacher policy 可以写成:
$$ q_\theta(\cdot\vert x,z,\hat y_{< t}) $$
其中 $z$ 表示 teacher 额外可见的信息。student 先在自己的策略下采样:
$$ \hat y\sim\pi_\theta(\cdot\vert x) $$
然后在 student rollout 上最小化 teacher 和 student 的 token-level 分布差异:
$$ \mathcal L(\theta)=\mathbb E_{(x,z)}\mathbb E_{\hat y\sim \pi_\theta(\cdot\vert x)}\left[\sum_{t=1}^{|\hat y|}\mathcal D\left(q_\theta(\cdot\vert x,z,\hat y_{< t})\Vert \pi_\theta(\cdot\vert x,\hat y_{< t})\right)\right] $$
三篇论文的差别主要在于 $z$ 的来源:
- 在 SDFT 里,$z$ 是 expert demonstration
- 在 SDPO 里,$z$ 是 environment feedback,或者成功 rollout 提供的隐式反馈
- 在 OPSD 里,$z$ 是 ground-truth answer / verified solution
因此,这一类方法更接近 privileged-context distillation:先让 teacher 在更多上下文下形成一个更优的条件分布,再把这个分布蒸馏回 student。
Self-Distillation Enables Continual Learning
这篇Self-Distillation Enables Continual Learning讨论的是 continual learning:只有 demonstration,没有显式 reward,如何做 on-policy 学习并尽量减少 catastrophic forgetting。
Method
给定任务输入 $x$ 和 demonstration $c$:
- student 只看到 $x$
- teacher 看到 $x,c$
SDFT 在 student 自己生成的轨迹上最小化 reverse KL:
$$ L(\theta)=D_{KL}(\pi_\theta(\cdot\vert x)\Vert \pi(\cdot\vert x,c)) $$
这里的关键点有两个:
- 训练是 on-policy 的,因为轨迹来自当前 student,而不是离线 demo
- teacher 的作用不是复述 demonstration,而是利用 ICL 根据 demonstration 形成一个 demonstration-aware policy
这篇论文更重要的部分,是把这个目标改写成一个 trust-region RL 问题。标准形式为:
$$ \pi_{k+1}=\arg\max_\pi \mathbb E_{y\sim \pi}[r(y,x)]-\beta D_{KL}(\pi(\cdot\vert x)\Vert \pi_k(\cdot\vert x)) $$
它的最优策略满足:
$$ \pi_{k+1}^*(y\vert x)\propto \pi_k(y\vert x)\exp(r(y,x)/\beta) $$
整理后可以得到 reward 的等价表达:
$$ r(y,x)=\beta\left(\log \pi_{k+1}^*(y\vert x)-\log \pi_k(y\vert x)\right)+C $$
真正的难点在于 $\pi_{k+1}^*$ 是未知的。论文在这里引入了 ICL assumption:
$$ \pi_{k+1}^*(y\vert x)\approx \pi(y\vert x,c) $$
也就是说,给定 demonstration 之后,同一个模型在 ICL 条件下形成的 teacher 分布,近似于“理解了任务意图之后的更优策略”。
将这个假设代回去,就得到 SDFT 对应的隐式 reward:
$$ r(y,x,c)=\log \pi(y\vert x,c)-\log \pi_k(y\vert x) $$
如果进一步拆到 token 级别:
$$ r_t(y_t\vert y_{<t},x,c)=\log\frac{\pi(y_t\vert y_{<t},x,c)}{\pi_k(y_t\vert y_{<t},x)} $$
因此,demonstration 并不是直接变成监督标签,而是先通过 ICL 改变了同一个模型的条件分布;随后,teacher/student 的 log-prob 差被解释成 reward。此时 policy gradient:
$$ \nabla J(\pi_k)=\mathbb E_{y\sim \pi_k}\left[\log\frac{\pi(y\vert x,c)}{\pi_k(y\vert x)}\nabla \log \pi_k(y\vert x)\right] $$
在期望上就与最小化
$$ D_{KL}(\pi_k(\cdot\vert x)\Vert \pi(\cdot\vert x,c)) $$
的梯度等价。于是整条链路可以写成:
- demonstration 激活 teacher 的 ICL 能力
- teacher 形成一个更懂任务意图的条件策略
- teacher/student 分布差被重写成隐式 reward
- student 在自己的 on-policy 轨迹上朝这个 reward 更高的方向更新
这也是这篇论文将 self-distillation 解释为 implicit IRL 的核心逻辑。
Experiment
实验结果集中说明了三件事:
- 在 skill learning 中,SDFT 相比 SFT、DFT、SFT + Re-invoke 取得了更好的 Pareto front,同时提升新任务能力并保留原有能力。
- 在 knowledge acquisition 中,SDFT 在 strict / lenient / OOD 三个指标上分别达到 89 / 100 / 98,而 SFT 为 80 / 95 / 80。
- 在 sequential learning 设置下,SDFT 能持续累积多个技能,而顺序 SFT 出现明显遗忘。
- 方法效果高度依赖模型的 ICL 能力,模型规模越大,SDFT 相对 SFT 的优势越明显。
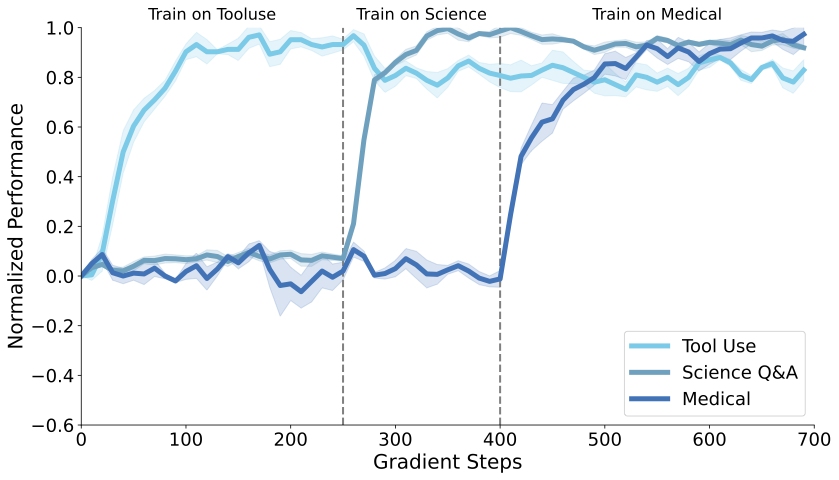
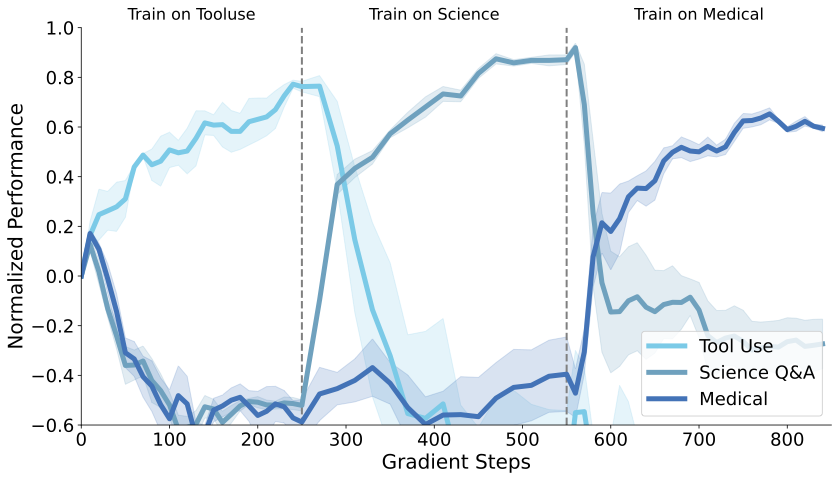
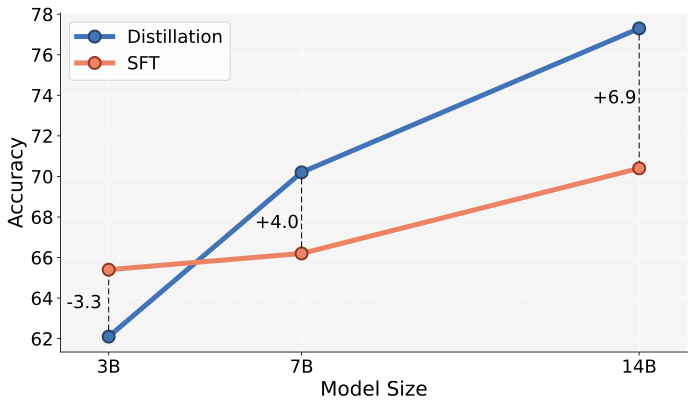
Summary
SDFT 可以看作“从 demonstrations 中做 on-policy 学习”的一种实现:没有显式 reward model,但 demonstration 通过 teacher 的 ICL 形成了一个可优化的隐式 reward。
Reinforcement Learning via Self-Distillation
这篇Reinforcement Learning via Self-Distillation关注 RLVR / tool use / coding 里的 credit assignment 问题:环境给出的反馈通常是 sequence-level 的,但训练真正需要的是 token-level 信号。
Method
设模型生成一次回答 $y$,环境返回反馈 $f$。此时:
- student:$\pi_\theta(\cdot\vert x)$
- self-teacher:$\pi_\theta(\cdot\vert x,f)$
也就是说,模型先在无反馈条件下完成一次 rollout,再在“看到了反馈”的条件下重新评估这条原始轨迹。
SDPO 的关键量是 token-level advantage:
$$ A_{i,t}^{\text{SDPO}}(\hat y_{i,t})=\log\frac{\pi_\theta(\hat y_{i,t}\vert x,f_i,y_{i,< t})}{\pi_\theta(\hat y_{i,t}\vert x,y_{i,< t})} $$
与之对比,GRPO 通常把同一个 scalar reward 平均分配到整条序列的所有 token:
$$ A^{\text{GRPO}}_{i,t}=r_i-\text{mean}({r_i}) $$
这意味着:
- GRPO 给的是 sequence-level 的粗粒度 credit
- SDPO 给的是 token-level,甚至 logit-level 的 hindsight credit
这一设计使得环境反馈和模型自身的 retrospection 能力被组合起来:环境只负责提供“发生了什么”,self-teacher 负责把这些信息翻译成更密集的训练信号。
Experiment
这篇论文的实验集中体现了 dense credit assignment 的收益:
- 在 scientific reasoning 和 tool use 任务上,SDPO 的最终 aggregate accuracy 高于强 GRPO baseline。
- 训练速度明显更快。在 Chemistry 任务上,Olmo3-7B-Instruct 使用 SDPO 在约 50 分钟即可达到 GRPO 训练约 5 小时附近的效果。
- 生成长度显著缩短,平均可以比 GRPO 更短,同时维持更高准确率。
- 即使环境只有 scalar reward,也可以把 successful rollouts 作为 failed attempts 的隐式反馈继续做 self-distillation。
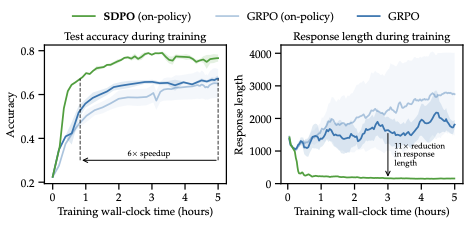
Summary
SDPO 的核心不是“把 distillation 用在 RL 上”,而是把环境反馈转成 hindsight teacher context,再通过 teacher/student 的分布差完成 dense credit assignment。
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
这篇Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models将 self-distillation 放到 reasoning post-training 场景中,目标是用答案或参考解作为 privileged context,替代外部 teacher 或高成本 RL。
Method
给定问题 $x$ 和标准答案或参考解 $y^*$:
- student 只看到 $x$
- teacher 看到 $x,y^*$
student 先生成自己的推理轨迹 $\hat y$,然后 teacher 和 student 都在同一个 student prefix 上计算下一 token 分布,并最小化 per-token divergence:
$$ L_{\text{OPSD}}(\theta)=\mathbb E_{(x,y^*)}\mathbb E_{\hat y\sim p_S(\cdot\vert x)}\left[\sum_{n=1}^{|\hat y|}D\left(p_T(\cdot\vert x,y^*,\hat y_{<n})\Vert p_S(\cdot\vert x,\hat y_{<n})\right)\right] $$
其中 $D$ 可以取 forward KL、reverse KL 或 JSD。
这篇工作的出发点很明确:对于 reasoning 任务,同一个模型在“看到了正确解”的条件下,通常更容易判断自己原始推理轨迹中哪些位置更合理、哪些位置需要修正。于是标准答案不再只是最终监督信号,而成为生成 teacher distribution 的 privileged context。
Experiment
实验结果主要体现为 token efficiency:
- 在 Qwen3-8B 上,四个数学 benchmark 的平均分从 base 的 50.0 提升到 52.2,GRPO 为 51.3,SFT 为 50.0。
- 在 Qwen3-4B 上,平均分从 48.3 提升到 50.4,优于 SFT,并与 GRPO 持平或略优。
- 在 1.7B 规模上效果不稳定,说明方法同样依赖基础模型能力。
- 相比需要更多 rollout 的 GRPO,OPSD 用单 rollout 即可获得可比性能,token efficiency 更高。
- full-vocabulary 的 logit distillation 优于只优化 sampled token,说明 teacher 的价值来自整个局部分布,而不只是采样动作。
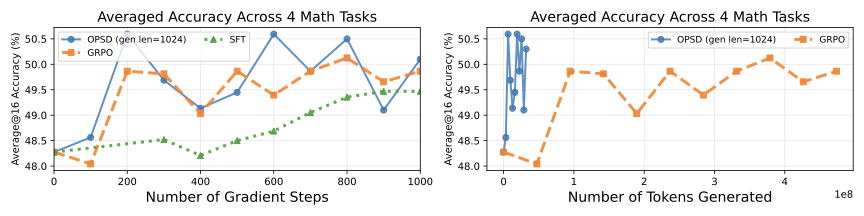
Summary
OPSD 将 reasoning dataset 中的答案或参考解转成 teacher context,本质上是在 reasoning post-training 里复用 on-policy distillation,而不是依赖外部 teacher 或纯 outcome-level RL。
Comparison
这三篇论文虽然任务设定不同,但方法结构高度一致:
| Paper | Privileged Context | Main Setting | Main Signal | Main Gain |
|---|---|---|---|---|
| SDFT | demonstration $c$ | continual learning / learning from demos | implicit reward from demo-conditioned teacher | 更少遗忘,更好的知识注入与技能累积 |
| SDPO | feedback $f$ | RL / tool use / coding / reasoning with environment | dense hindsight credit assignment | 比 GRPO 更快、更短、更 dense |
| OPSD | verified solution $y^*$ | reasoning post-training | answer-conditioned token-level distillation | 更高 token efficiency,不依赖外部 teacher |
从统一视角看,这三篇工作共同强调了四点:
- teacher 和 student 共享参数,差异来自可见信息而不是模型规模
- 训练都发生在 student 自己的 on-policy 轨迹上
- 目标都是把稀疏、离线或高层信号变成 dense token-level supervision
- 方法效果都高度依赖模型自身的 ICL / retrospection 能力
因此,self-distillation 在这些工作中的作用,不是简单替代 SFT 或 RL,而是在两者之间增加了一层更细粒度的中间结构:把 privileged context 转译成 on-policy dense supervision。
References
[1] Idan Shenfeld et al. “Self-Distillation Enables Continual Learning” arXiv preprint arXiv:2601.19897 (2026).
[2] Jonas Hübotter et al. “Reinforcement Learning via Self-Distillation” arXiv preprint arXiv:2601.20802 (2026).
[3] Siyan Zhao et al. “Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models” arXiv preprint arXiv:2601.18734 (2026).