Overview
很多大语言模型系统的性能差距,并不来自权重本身,而来自权重外那层持续读写上下文、维护状态、拼接提示词、调用工具的外围代码。论文 Meta-Harness: End-to-End Optimization of Model Harnesses 把这层代码统一称为 harness(模型外围控制代码),并把问题重新表述成:如果模型权重固定,能否直接搜索“围绕模型的程序”本身,而不是继续手工调 prompt、手工调记忆规则?
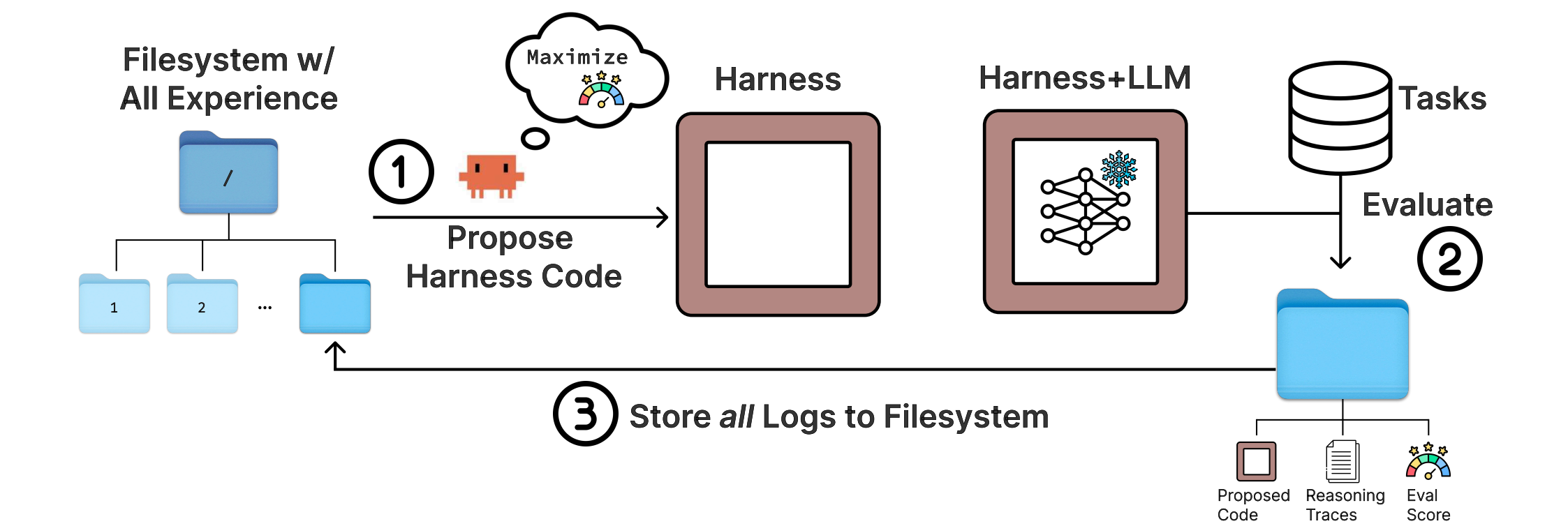
这篇工作的切入点很直接。现有很多文本优化方法只看分数、短摘要,或者只保留最近几轮反馈;但 harness 的错误往往是长程的。某一次错误的记忆写入、某一条错误的检索规则、某一个提示词里的多余约束,都可能在后续很多步之后才表现成失败。Meta-Harness 的做法是把所有候选 harness 的源码、分数和执行轨迹都保存在文件系统(filesystem)里,再让一个编码代理(coding agent)自己决定读什么、改什么、验证什么。
论文在三个任务上验证了这件事:在线文本分类、奥赛级数学推理检索、以及 TerminalBench-2 上的长程编码代理。结果显示,这种“搜索 harness 的 harness”不仅能超过手工设计的基线,还能自动发现一些非常具体、但又具备迁移性的策略。
Motivation
这篇论文的动机并不复杂,但很容易被低估。
第一,harness engineering(harness 工程)已经是大模型系统里的主要性能变量之一。对于固定底座模型,改变“存什么、取什么、何时取、怎样展示给模型”这些外围逻辑,往往可以带来数量级明显的性能差异。问题在于,这件事目前主要靠人工迭代:读失败案例、猜故障原因、改代码、再测一轮。
第二,很多现有文本优化方法并不适合这个问题。论文总结了几类常见限制:
- 只条件在标量分数上,几乎看不到失败的具体路径;
- 只保留短摘要,很多诊断细节在压缩时就丢掉了;
- 只看最近窗口,无法追溯更早的设计决策怎样影响后续行为。
这类压缩在 prompt 优化里还能成立,在 harness 搜索里就会变得很脆弱。因为 harness 是一个会跨多步运行的程序。一次“把哪段中间状态写进记忆”的选择,可能要到很多步之后,才以错误检索、错误决策、上下文膨胀等形式暴露出来。论文给出的对比非常有代表性:此前代表性文本优化工作每次迭代可利用的上下文规模大致在 100 到 30,000 token,而本文研究的 harness 搜索场景里,单次评估可以产生最高约 10,000,000 token 的诊断信息。若只看摘要,很多真正有因果价值的信号会被直接抹平。
Problem Formulation
论文先把问题写成一个非常干净的目标优化式。
设 $M$ 是固定的大语言模型,$X$ 是任务分布,$H$ 是一个 harness。对于任务样本 $x \sim X$,系统在 harness $H$ 的控制下运行,并产生一条轨迹 $\tau \sim p_M(H, x)$。这里的轨迹包含提示词构造、模型回复、状态更新、工具调用等全过程。最终由任务相关的奖励函数 $r(\tau, x)$ 给出得分。
于是,目标就是找到期望奖励最大的 harness:
这个式子里每个符号的含义都很具体:
- $H$ 决定模型每一步究竟看到什么上下文;
- $p_M(H,x)$ 表示在固定模型 $M$ 下,由 harness 诱导出的执行分布;
- $r(\tau, x)$ 只关心最后任务做得好不好,比如分类准确率、数学题通过率、代理任务 pass rate。
当目标不止一个时,论文不把它们硬压成单一标量。例如文本分类场景既关心准确率,也关心额外上下文开销。论文采用帕累托前沿(Pareto frontier)筛选候选,而不是事先写死一个权重和。按论文的描述整理,这相当于保留那些“没有被别的 harness 同时在精度上更好、在成本上更低地支配”的程序。
Methodology
Search Loop as a Program Search Procedure
Meta-Harness 的核心并不是一套复杂的搜索启发式,而是一个很克制的外循环:
- 维护一个候选 harness 集合,以及每个候选的代码、分数、执行轨迹;
- 让编码代理读取文件系统中的历史经验;
- 由代理提出一个或多个新 harness;
- 评估这些 harness;
- 把新一轮代码、分数、轨迹全部写回文件系统;
- 最后在帕累托前沿上挑选候选并做测试集评估。
这一步的关键不是“演化”两个字,而是反馈接口的设计。此前很多方法会把历史候选压成简短摘要,再交给提议器;Meta-Harness 则把原始材料保留下来,让代理自己检索。论文在最复杂的设定下统计到,提议器每轮中位数会读取 82 个文件,并引用 20 多个历史候选。这个读法明显更像调程序,而不是只做提示词重写。
从这个角度看,Meta-Harness 真正优化的是一个更上层的接口设计:给定有限上下文窗口,什么样的外部记忆形式最适合让代理“归因”失败。论文的答案是文件系统。因为文件系统天然支持稀疏访问,代理可以只打开最可疑的若干段代码和日志,而不需要把所有历史一次性塞进提示词。
Why Raw Traces Matter
论文专门做了一个很有说服力的消融实验。在线文本分类里,如果提议器只能看到分数,或者只能看到“分数加摘要”,搜索效果都明显差于完整接口。完整接口允许代理读取原始执行轨迹(execution trace),它不只知道某个 harness 失败了,还能追溯失败是由检索逻辑、提示模板、还是状态更新规则引起的。
这类差异之所以大,原因在于 harness 的改动往往是结构性的。比如,问题可能不在于“再写一段更强的系统提示词”,而在于“把一次大调用拆成两次短调用”“先做草稿判断,再做反例验证”“把检索策略从统一规则改成按学科路由”。这些改动很难从一个分数或者一句总结里逆推出来源,但从原始轨迹里通常能看出来。
Discovered Classification Harnesses
在线文本分类任务里,Meta-Harness 并没有收敛到单一模板,而是找到了一条精度和上下文成本之间的策略前沿。论文附录里给出了两个代表性程序。
第一类是 Draft Verification。这个 harness 先用少量相似样本做一次草稿标签(draft label)预测,再根据这个草稿标签回到记忆里找支持样本和挑战样本,让模型做一次“维持还是修正”的复核。这里最有意思的点在于,第二次检索不再是普通近邻检索,而是“条件在当前草稿答案上的反事实检索”。它检索的目标变成了:当前猜测最可能错在哪。
第二类是 Label-Primed Query。这个程序先显式列出标签空间,再给每个标签找一个与当前查询最相关的代表样本,最后再补一组“高度相似但标签不同”的对比样本。这样做的效果是,模型一方面看到了完整标签空间,另一方面也看到了当前输入附近最容易混淆的决策边界。
这两个程序都不是靠人工预写模板得到的,而是搜索过程中从失败轨迹里逐渐长出来的。这也解释了论文为什么强调 harness 搜索发生在代码空间(code space)里:代理真正改的是程序控制流,而不只是自然语言表面文本。
Discovered Math Retrieval Harness
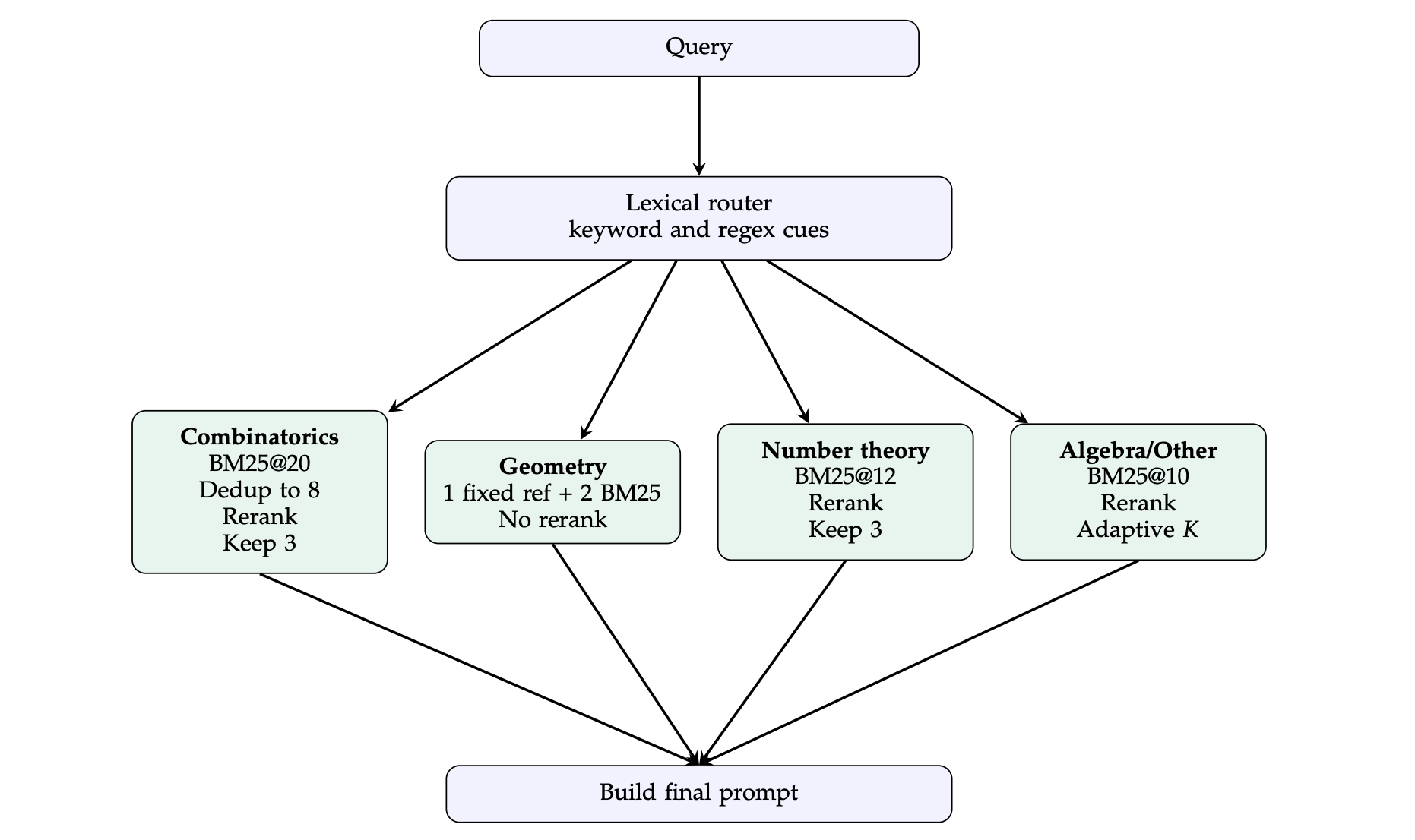
数学推理部分的发现更加程序化。论文最后选中的 harness 是一个四路 BM25(基于词项匹配的稀疏检索)路由器:先用词汇和正则特征判断题目大类,再按组合、几何、数论、代数/其他四个分支走不同检索策略。
这个 harness 的细节很值得看:
- 组合数学分支先取 20 个 BM25 候选,再去重到 8 个,按词法分数和题目难度重排,最后保留 3 个;
- 几何分支固定注入 1 个 NuminaMath 参考样例,再补 2 个原始 BM25 邻居,不做额外重排;
- 数论分支会给“较早显式写出技巧”的解答额外加分;
- 默认分支根据顶部检索分数是否集中,动态决定保留几个样例。
这说明 Meta-Harness 学到的并不是“检索总比不检索好”这种空泛结论,而是一个非常细粒度的策略:不同数学子领域,需要不同的检索多样性、难度匹配和样例数量控制。
Discovered TerminalBench Harness
TerminalBench-2 部分最有意思,因为它展示了 Meta-Harness 可以发现一个非常小、但非常值钱的系统级改动。搜索最终保留的 harness 建立在 Terminus-KIRA 之上,沿用了原有的原生工具调用、30KB 输出上限和多视角完成检查;新加进去的核心模块只有一个:在第一轮模型调用之前,先执行一次环境快照(environment bootstrap)。
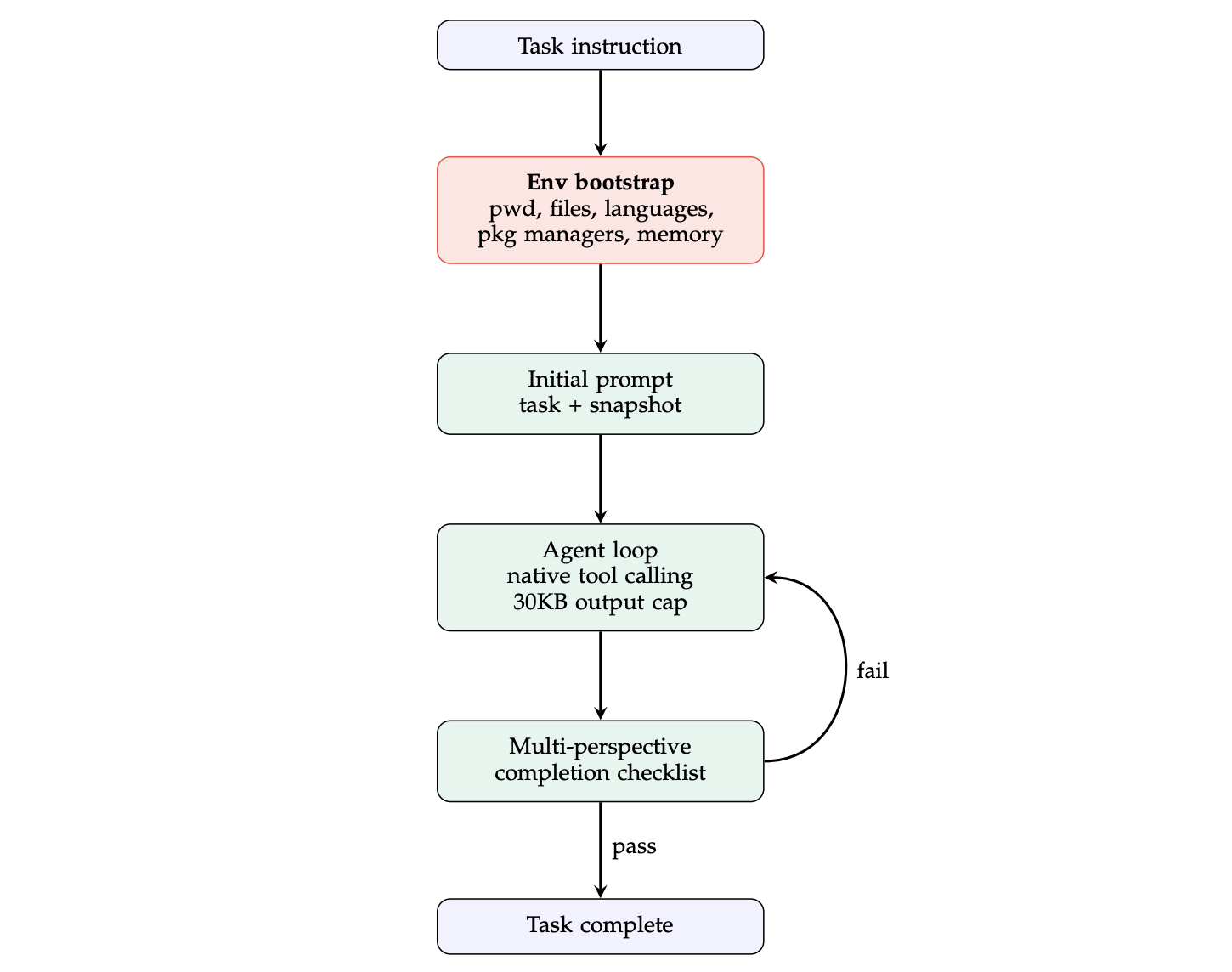
这条改动的逻辑非常明确。很多长程代理任务失败,不是因为模型不会做,而是因为前 2 到 4 轮都在摸清环境:当前工作目录在哪、/app 里有什么、安装了哪些语言、能不能 pip、有没有 apt-get、系统内存多大。Meta-Harness 发现,只要在任务开始前用一个带超时保护的 shell 命令把这些信息统一抓出来,再作为 [Environment Snapshot] 塞进初始提示词,就可以减少早期探索回合,把预算留给真正的问题求解。
这类改动特别能说明论文的主张。它不是更华丽的 prompt,也不是更强的 reranker,而是一个非常像资深工程师会做的系统补丁:先把环境事实摆在台面上,再让代理开始推理。
Experiments
Setup
论文在三个场景上做实验。
在线文本分类使用 GPT-OSS-120B 作为底座模型,任务是随着带标签样本逐个到来,持续维护记忆并在测试集上预测类别。搜索初始化包含 zero-shot、few-shot、ACE(Agentic Context Engineering,上下文工程代理)和 MCE(Meta Context Engineering,元上下文工程)等基线,运行 20 轮演化、每轮 2 个候选,总计 40 个候选 harness。
数学推理部分使用一个去重、去污染后的 50 万以上题解语料库,让 Meta-Harness 只在 BM25 检索堆栈上做代码级策略搜索,而不是引入新的稠密编码器。搜索集是 250 道奥赛难度题,最终在 200 道此前未见的 IMO 级问题上,跨 5 个未参与搜索的模型做评估。
TerminalBench-2 则把搜索本身当成 benchmark discovery problem。搜索起点是 Terminus 2 和 Terminus-KIRA 两个强基线,最终在完整 89 个任务上报告 Opus 4.6 和 Haiku 4.5 的 pass rate。
Main Results
文本分类里,论文主结果非常强。最终选出的 Meta-Harness 在三个测试集上的平均准确率达到 48.6%,超过 ACE 的 40.9% 和 MCE 的 40.0%。更重要的是,这个结果不是用更多上下文换来的:Meta-Harness 的额外上下文只有 11.4K token,而 ACE 是 50.8K,MCE 是 28.5K。放到 9 个完全未参与搜索的 OOD 数据集上,Meta-Harness 的平均准确率依然达到 73.1%,高于 ACE 的 70.2%。
数学推理里,单个搜索得到的检索 harness 跨 5 个 held-out 模型都带来了收益。平均 pass@1 从无检索的 34.1% 提升到 38.8%,平均提升 4.7 个点;同时也略高于固定的 BM25 检索基线 37.5%。这个结果说明,性能提升主要来自“怎样检索”,而不是“是否检索”。
TerminalBench-2 上,Meta-Harness 在 Claude Opus 4.6 上得到 76.4% 的 pass rate,高于 Terminus-KIRA 的 74.7%;在更弱的 Claude Haiku 4.5 上达到 37.6%,超过当时公开报告的 Goose 35.5%,位列 Haiku 4.5 代理第一。
Ablations and Search Behavior
论文最关键的消融,是比较提议器能看到多少历史信息。在线文本分类里:
- 只看分数时,中位数准确率 34.6%,最佳 41.3%;
- 看分数加摘要时,中位数 34.9%,最佳 38.7%;
- 看完整执行轨迹时,中位数 50.0%,最佳 56.7%。
这个差距说明,执行轨迹不是“锦上添花”的额外日志,而是 harness 搜索的主要诊断信号。
另一条结果也很重要。和 OpenEvolve、TTT-Discover 这些文本优化方法相比,Meta-Harness 在文本分类设置里只用约十分之一的评估次数,就达到了对方最终精度附近;继续搜索后,最终精度还高出 10 个点以上。论文把这个优势归因于一件事:外循环尽量少写死结构,把归因和修改职责交给代理本身。
Limitations
这篇论文结果很强,但边界也比较清楚。
第一,方法目前明显依赖强编码代理。论文实验中使用的是 Claude Code 搭配 Opus-4.6,作者也在讨论部分明确指出,不同 proposer 的效果差异还没有系统研究。换句话说,Meta-Harness 展示的是“这类接口在强代理条件下可行”,还不是“任何代理都能稳定复现”。
第二,TerminalBench-2 的设定本身就是 benchmark-specific discovery。论文解释说,公开社区本来就在围绕这个 benchmark 持续迭代 harness,因此使用同一个 89 任务集合做搜索和最终报告是现实可行的 discovery protocol;同时作者也做了人工检查和正则审计以排除显式泄漏。但这类设定天然更接近“公开竞赛中的自动化 harness 工程”,而不是严格的分布外泛化评测。
第三,这篇工作优化的是权重外程序,而不是模型参数本身。作者在讨论里提出,下一步很自然的方向是让 harness 和权重共同演化。若只优化 harness,能解决的是推理期流程、上下文管理和工具使用问题;模型内部表征本身的缺陷,仍然需要参数层面的更新去补。
References
[1] Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. “Meta-Harness: End-to-End Optimization of Model Harnesses” arXiv preprint arXiv:2603.28052 (2026).
[2] Yoonho Lee. “Meta-Harness Project Page” project page.
[3] Stanford IRIS Lab. “meta-harness-tbench2-artifact” GitHub repository.
[4] Qizheng Zhang, Changran Hu, Shubham Upasani, Boyuan Ma, Fenglu Hong, V. Kamanuru, Jay Rainto, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kouluton. “Agentic Context Engineering: Evolutionary Search over Contexts for Improving Language Models” arXiv preprint arXiv:2510.04618 (2025).